Running a routing performance check on my blog I noticed that in the list of domains being accessed included facebook.com. Except, I don't have anything to do with Facebook on my blog and I certainly don't want to be adding to their tracking.
I was rather pissed that my blog contributes to Facebook's data so it was time to eject Disqus and look at the alternatives.
Disqus is free…but not free at all
When you're not paying in cash, you're paying in another way. I should have been a bit more tuned in, but it fairly obvious (now…) that Disqus' product is you and me.
As Daniel Schildt / @autiomaa pointed out on twitter
Disqus is even worse when you realise that their main product data.disqus.com is their own tracking dataset.
"The Web's Largest First-Party Data Set"
Not cool. I do not want to be part of that, nor be forcing my unwitting reader to become part of that. So, what are the options?
Options
I'd already been window shopping for an alternative commenting system. There's a few github based systems that rely on issues. It's cute, but I don't like the idea of relying so tightly on a system that really wasn't designed for comments. That said, they may work for you.
There's also a number of open source & self hosted options - I can't vouch for them all, but I would have considered them as I'm able to review the code.
All of these options would be ad-free, tracking free, typically support exported Disqus comments and be open source. I personally settled on Commento for a few reasons:
- "Cloud" (ie. commercial) and self-hosted option
- Open source and accepting issues and merge requests
- User interface was clean and polished
I've opted to take the commercial route a pay for the product for the time being. Though there's some fine print about 50K views per month limit - and I'm hoping that's a soft limit because although my blog sits around 40K, a popular article like my CLI: Improved kicked me into the 100K views in a month and shot the post into 1st place on my popular page.
That said, if I do run into limits, I can move to a self hosted version with Scaleway or DigitalOcean or the like for €3-$5 a month.
The initial setup was very quick (under 60 minutes to being ready to launch) but I ran into a couple of snags which I've documented here.
Commento TL;DR
These are the snags that I ran into and fixed along the way. It may be that none of this is a problem for you, but it was for me.
- Testing offline isn't possible because the server reads the browser's location
- If disqus' comment URLs don't match the post URLs (for any reason) the comments won't appear
- Ordered by oldest to newest
- Avatars are lost in export to import
- Performance optimisations could be done (local CSS, accessibly colour contrast, etc)
If you want to use my commento.js and commento.css you're welcome to (and these are the contrast changes).
That all said and done, the comments are live, and look great now that I'm not feeding the Facebook beast.
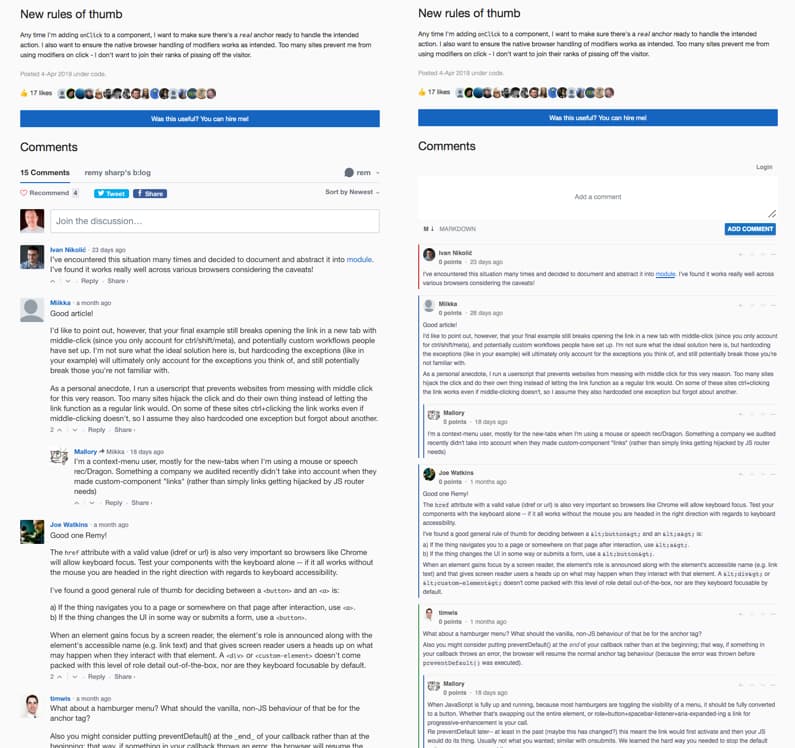
Testing Commento offline & adjusting urls
The commento.js script will read the location object for the host and the path to the comments. This presents two problems:
- Testing offline isn't possible as the host is
localhost - When I migrated from one platform to another (back from wordpress to my own code), my URLs dropped the slash - this means that no comments are found for the page
The solution is to trick the Commento script. The JavaScript is reading a parent object - this is another name that the global window lives under (along with top, self and depending on the context, this).
So we'll override the parent:
window.parent = {
location: {
host: 'remysharp.com',
pathname: '/2019/04/04/how-i-failed-the-a/'
}
};
Now when the commento.js script runs, both works locally for testing, but also loads the right path (in my case I'm actually using a variable for everything right before the trailing /).
Caveat: messing with the parent value at the global scope could mess with other libraries. Hopefully that don't rely on these globals anyway.
Alternative self hosted solution
Another methods is to download the open source version of commento.js front end library and make a few changes - which is what I've needed to do in the end.
Firstly, I created two new variables: var DOMAIN, PATH and when the code read the data-* attributes off the script, I also support reading the domain and reading the page:
noFonts = attrGet(scripts[i], 'data-no-fonts');
DOMAIN = attrGet(scripts[i], 'data-domain') || parent.location.host;
PATH = attrGet(scripts[i], 'data-path') || parent.location.pathname;
I'm using the commento.js script with data attributes, which in the long run, is probably safer than messing with parent:
<script defer async
data-path="/2019/04/04/how-i-failed-the-a/"
data-domain="remysharp.com"
src="/js/commento.js"></script>
It's important that the self-hosted version lives in /js/commento.js as it's hard coded in the commento.js file.
Ordered by most recent comment
By default, Commento shows the first comment first, so the newest comments are at the end. I prefer most recent at the top.
With the help of flex box and some nice selectors, I can reverse all the comments and their sub-comments using:
#commento-comments-area > div,
div[id^="commento-comment-children-"] {
display: flex;
flex-direction: column-reverse;
}
Preserving avatars
During the import process from disqus to commento, the avatars are lost. Avatars add a nice feeling of ownership and a reminder that there's (usually) a human behind the comment, so I wanted to bring these back. This process is a little more involved though.
This required a little extra mile. The first step is to capture all the avatars from disqus and upload them to my own server. Using the exported disqus XML file, I'm going to grep for the username and real name, download the avatar from disqus using their API and save the filename under the real name.
I have to save under the real name as that's the only value that's exposed by commento (though in the longer run, I could self-host commento and update the database avatar field accordingly). It's a bit gnarly, but it works.
This can all be done in single line of execution joining up unix tools:
$ grep '<username>' remysharp-2019-06-10T16:15:12.407186-all.xml -B 2 |
egrep -v '^--$' |
paste -d' ' - - - |
sort |
uniq |
grep -v "'" |
awk -F'[<>]' '{ print "wget -q https://disqus.com/api/users/avatars/" $11 ".jpg -O \\\"" $3 ".jpg\\\" &" }' |
xargs -I CMD sh -c CMD
You might get away with a copy and paste, but it's worth explaining what's going on at each stage in case it goes wrong so hopefully you're able to adjust if you want to follow my lead. Or if that worked, you can skip to the JavaScript to load these avatars.
How the combined commands work
In little steps:
grep '<username>' {file} -B 2
Find the instance of <username> but include the 2 previous lines (which will catch the user's name too).
egrep -v '^--$'
When using -B in grep, it'll separate the matches with a single line of --, which we don't want, so this line removes it. egrep is a "regexp grep" and -v means remove matches, then I'm using a pattern "line starts with - and ends with another -".
paste -d' ' - - -
This will join lines (determined by the number of -s I use) and join them using the delimiter ' ' (space).
sort | uniq
When getting unique lines, you have to sort first.
grep -v "'"
I'm removing names that have a dash (like O'Connel) because I couldn't escape them in the next command and it would break the entire command. An acceptable edge case for my work.
awk -F'[<>]' …
This is the magic. awk will split the input line on < and > (the input looking like <name>Remy</name><isAnonymous>false</isAnonymous><username>rem</username> which came from the original grep). Then using the { print "wget …" } I'm constructing a wget command that will request the URL and save the jpeg under the user's full name. Importantly I must wrap the name in quotes (to allow for spaces) and escape those quotes before passing to the next command.
xargs -I CMD sh -c CMD
This means "take the line from input and execute it wholesale" - which triggers (in my case, 807) wget requests as background threads.
If you want learn more about the command line, you can check out my online course (which has a reader's discount applied 😉).
The whole thing runs for a few seconds, then it's done. In my case, I included these in my images directory on my blog, so I can access them via avatars/rem.jpg.
{kind=link}
JavaScript to load these avatars
Inside the commento.js file, when the commenter doesn't have a photo, the original code will create a div, colour it and use the first letter of their name to make it look unique.
I've gone ahead and changed that logic so that it reads:
If there's no photo, and the user is not anonymous, create an image tag with a data-src attribute pointing to my copy of the avatar. Then set the image source to my "no-user" avatar (I'll come on to why in a moment) and apply the correct classes for an image.
If and only if, the image fires the error event, I then create the originally Commento element and replace the failed image with the div.
Then, once Commento has finished loading, I apply an IntersectionObserver to load as required (rather than hammering my visitors network with avatar images that they may never scroll to) thanks to Zach Leat's tip this week.
avatar = create('img');
avatar.setAttribute(
'data-src',
`https://download.remysharp.com/comments/avatars/${
commenter.name
}.jpg`
);
classAdd(avatar, 'avatar-img');
avatar.src = '/images/no-user.svg';
avatar.onerror = () => {
var div = create('div');
div.style['background'] = color;
div.innerHTML = commenter.name[0].toUpperCase();
classAdd(div, 'avatar');
avatar.parentNode.replaceChild(div, avatar);
};
As I mentioned before, I'm using the IntersectionObserver API to track when the avatars are in the viewport, then the real image is loaded - reducing the toll on my visitor. However, I can only apply the observer once the images exist in the DOM.
To do this I need to configure Commento to let me do a manual boot using the data-auto-init="false" attribute on the script tag.
Once the script is loaded, in an inline deferred script I use this bit of nasty code, that keeps checking for the commento property, and once it's there, it'll call the main function - which takes a callback that I'll use to then apply my observer:
function loadCommento() {
if (window.commento && window.commento.main) {
window.commento.main(() => observerImages());
} else {
setTimeout(loadCommento, 10);
}
}
setTimeout(loadCommento, 10);
Note that this JavaScript only ever comes after the script tag with commento.js included. However, I had to make another change to the commento.js to ensure
Accessibility and performance
The final tweak was to get my lighthouse score up. There were a few issues with accessibility around contrast (quite probably because I use a slightly off-white background).
It didn't take too much though (I'm going to assume you're okay reading the nested syntax - I use Less, you might use SCSS, if not, remember to unroll the nesting):
body .commento-root {
.commento-logged-container .commento-logout,
.commento-card .commento-timeago,
.commento-card .commento-score,
.commento-markdown-button {
color: #757575;
}
.commento-card .commento-option-button,
.commento-card .commento-option-sticky,
.commento-card .commento-option-unsticky {
background: rgb(73, 80, 87);
}
}
I also moved to using a local version of the CSS file, using the data-css-override attribute on the script tag. The final change I made was in commento.js to add a (empty) alt attribute on my signed in avatar and added rel=noopener on the link to commento.io - both of which are worthwhile as pull requests to the project.
So that's it. No more tracking from Bookface when you come to my site. Plus, you get to try out a brand new commenting system. Then at some point, I'll address the final elephant in the room: Google Analytics…