Trailing slashes in URIs, or URLs or UDI (surprisingly). What the heck do they actually mean, do they have any user or technical value and should I be including them???
Inheritance from Unix
A slash in the URL is a hang over from Unix days. A slash / (not to be confused with a backslash \), denotes a directory separation.
In particular, web servers for many, many years have had a default mode that reads: if a user requests a directory and I (the web server) find index.html (or .htm if it were of the windows flavour), I (the server) will return that file (instead of a directory listing).
Out of the box, old and out of date Apache (one of the early web servers) could handle the following requests:
…and all 3 requests could serve completely different responses assuming the server doesn't apply any extra hidden logic or configuration.
The first will only match a file called remy with no extension, in the root of my web server.
The second will serve remy.html, and the third ("normally") would serve the index.html in the directory called remy.
On face value however, it's not entirely clear (to me) whether the first request for me remy is a file or a directory. Of course it can be both, but it's quickly becoming a mental minefield.
Aside: a file scheme has 3 slashes (compared to the two used after http) because the scheme for URLs is <proto>://<host>/<path> and since file (in most cases) has no host (it's your machine), it becomes file:///<path> (ref).
Today's static servers
Today much of these defaults have been ironed out into "sensible defaults" and you'll be able to drop a directory of html files into a service like Netlify (or equally something of your own making) and URL handing is resolved for you.
In fact, Netlify offers a checkbox configuration option (my favourite kind, found under deployment options) that lets you support requests to https://example.com/remy responds with remy.html and requests to remy/ responds with remy/index.html.

These are handled by redirects. How exactly Netlify do this I don't know (I'm sure it's somewhere), but AWS S3 buckets offer the same functionality, as does nginx, Apache and pretty much every other server (just not quite as nice as a checkbox).
In rewriting my blog backend software I had to generate all the static files myself and I have to consider whether my existing URL schema still worked (it is important to me that it still works and that my URLs live as long as I do).
How about my blog URLs?
If you're able to see the URL to this post, you'll see my blog post URL structure:
- Year
- Month
- Day
- Title (in "slug" form)
When I view this URL, I'm asking myself: what am I looking at?
Is it slashed-uri.html? Is it index.html? Is it a file designed to be served with a content type of text/html but without a file extension? Maybe this isn't a static site, and the slug is a database key, more akin to /post?date=2019-03-22&slug=slashed-uri?
With all that in mind, the question that now plagues me is:
Should this URL end in a slash?
Slash or not?
Let's see. Using Unix philosophy as a starting point, it would make sense that a post itself is a directory (even if a virtual one), that way all related assets (such as images, comments and so on) would live in the same directory. This alone seems like a really nice feature - all the related content lives together.
So a slash makes sense in this case. Then again, a trailing slash feels…a little superfluous to the interface to my content. It's just a character that someone (a visitor or someone else linking to my post) would need to type.
These "pretty URLs", ones don't have slashes at the end, are it's completely within a web server's capabilities to redirect a request to the intended destination.
But then…what if my visitor does include a slash at the end?
Slash and not?
Do I do both? Just recently I was checking my existing blog software and I realised I was getting a valid response from both of these URLs:
The new problem here is: which one is correct? Or more specifically, which is the canonical URL?
By some fluke, I had included the link rel in my posts, that will read:
<link rel="canonical" href="https://remysharp.com/2018/12/24/memfetch">
But shouldn't one redirect on the other? It seems a little weird that my server responds a 200 OK on both URLs. The canonical URLs are typically more useful for alternative pages (like an AMP formatted page, or perhaps a version hosted on a different URL, like Medium).
It's all a bit of a mess…
…and actually there's no rules. Which, is kinda good because it allows me to decide how my site should work, but means I keep flipping back and forth on what's the right way of doing URLs for my content.
In the end, for my rewrite of my blog software, I decided to generate named files so that a directory (for 2019) looks like this:
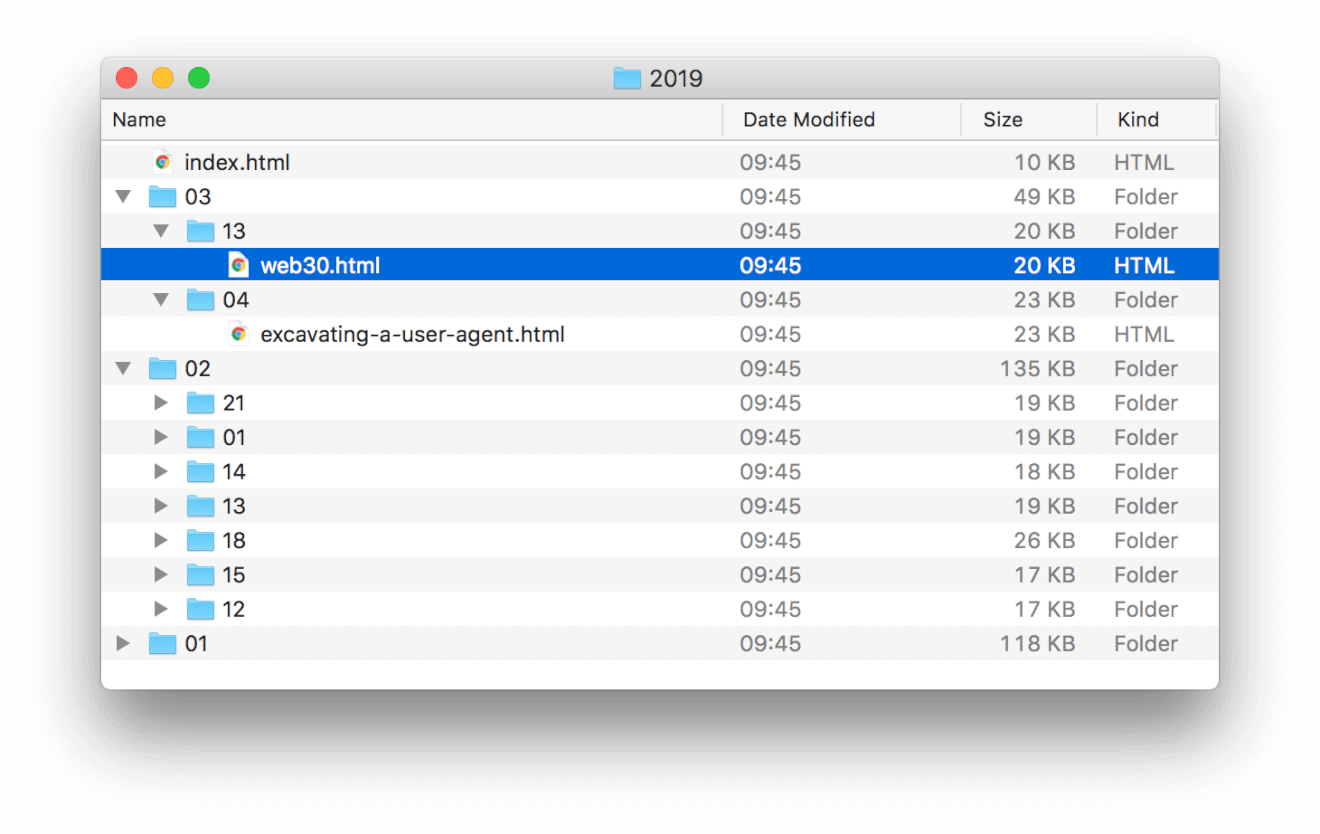
I chose to abandon the idea of having a directory for each post name only because the directories are generated from single markdown files, and the convenience of having a single file containing all the necessary information for the post was too great. Since my blog is mostly text it makes sense (in this case) to keep everything in a single file. Of course there's times I used images (as in this post), but all I need to do is make sure the image filename is unique enough so it doesn't collide with an existing filename (at 12 years of blogging it's yet to happen).