As modern JavaScript language features land more and more support I find myself using more and more of the syntactic sugar.
I'm a big fan of default arguments but I also really like the ...spread syntax. With that, I've found myself using spread syntax to get a list of unique elements, except until recently, I didn't understand what was under the hood.
Required reading
I'm always extremely wary of when I come across "X is an anti-pattern" posts. Mostly because the vast majority of the time, X is condemned without any real scientific proof.
Rich Snapp's article on the reduce({...spread}) anti-pattern is a welcome change with hard evidence that shows how the spread operator works. The crux of the anti-pattern is that spread is hidden iteration.
So after reading his article, I started scanning my code for this pattern, and as expected my code is littered with it.
Specifically: a method to get unique elements in an array.
How to get unique elements
A thing I love about code is that there's (usually) more than one way to solve a problem. That's when your creativity comes in to play.
Here's a few solutions (but far from comprehensive list) to getting the unique items in a list, starting with the anti-pattern:
// reduce spread
a.reduce((acc, curr) => (!acc.includes(curr) ? [...acc, curr] : acc), [])
// from new set
Array.from(new Set(a))
// reduce concat
a.reduce((acc, curr) => (!acc.includes(curr) ? acc.concat(curr) : acc), [])
// reduce push
a.reduce((acc, curr) => (!acc.includes(curr) && acc.push(curr) && acc || acc), [])
// filter
a.filter((curr, i) => a.indexOf(curr) === i)
The reduce spread pattern (in my case) has stemmed from wanting a single line of code (specifically without braces) so my alternative solutions are forced into the same pattern. This is fine (I think) until the "reduce push" pattern - but it's my constrains, so I'll take the ugly in this case.
Using my highly refined "finger in the air" technique to evaluating performance, and known now what I do about reduce spread, this is how I'd expect the code to perform, with slowest to fastest:
- reduce spread - because of hidden iteration
- from new set - potentially more complex object instantiation (hand wavy)
- reduce concat - though I'd expect this to be marginally slower than reduce push only because it has an additional instantiation of a new array
- reduce push
- filter - appears to have less work, less function calls than the reduce approaches
Actual results are surprising (or certainly to me):
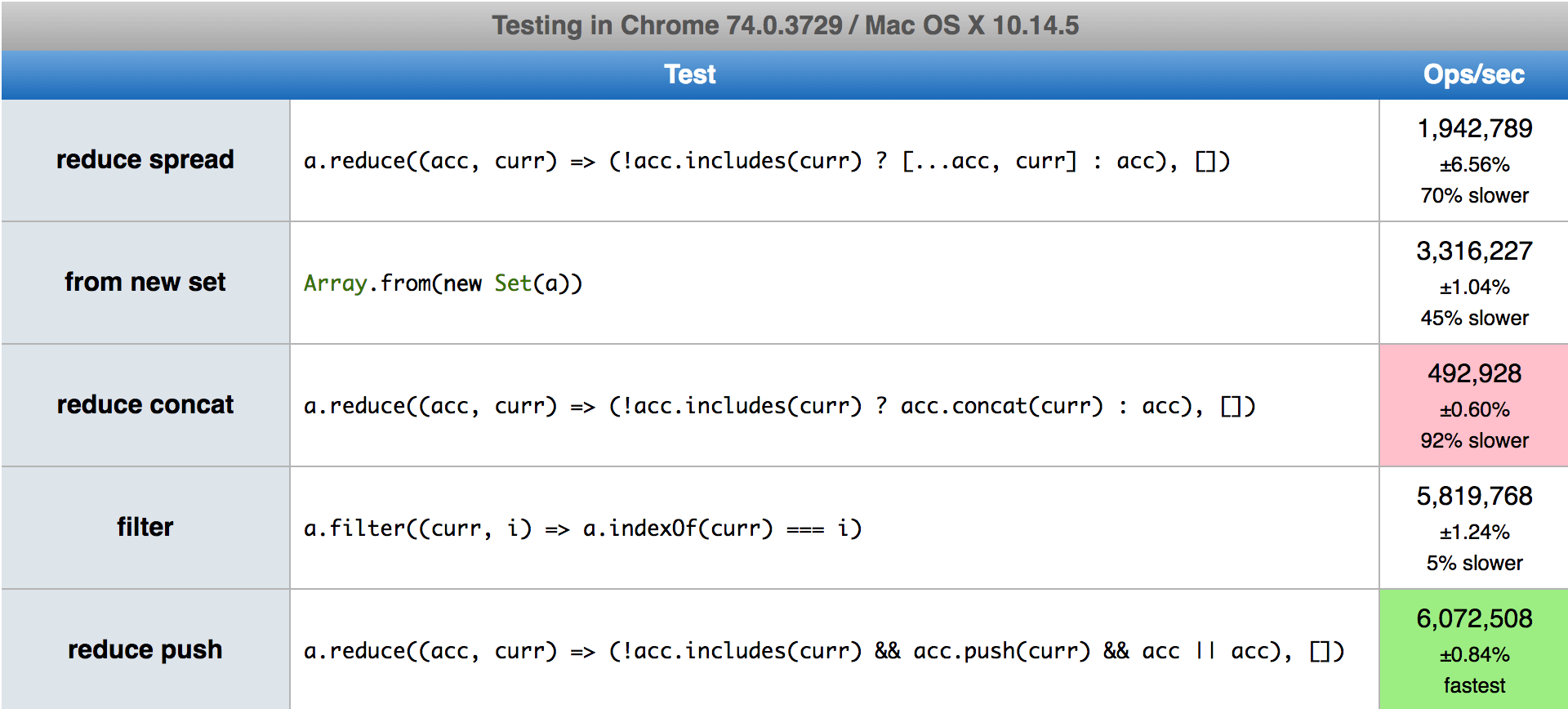
The fastest is the reduce push method, and the slowest, which surprised me the most, was the reduce concat method.
I don't know V8's engine well enough to know exactly what's going on under the hood, but given how clever I was trying to be with my code in the first place, it doesn't take much to adjust my ways to use the reduce push.
Although after all that investigation, the filter method came in a very close second place, and reads a lot simpler, so that's probably the right call. Just remember, if you're chaining a series of array methods, the filter will need to use the 3rd argument: .filter((curr, i, self) => self.indexOf(curr) === i).