The other week I finally pushed full offline access to my blog. I'd taken a lot of inspiration from Jeremy Keith's service worker from his blog.
One defining feature I wanted to support was that if you were offline and visited that page isn't cached, I wanted to list recent blog posts you had visited.
The effect
If you're a regular visitor of this blog then my service worker (only deployed in the last few weeks) will collect those posts you visit in a dedicated cache. If you then try to visit a URL that hasn't been cached, say a post or page like popular posts (and so on) you'll be presented with a page saying that the page isn't available offline but you can re-visit an existing post:
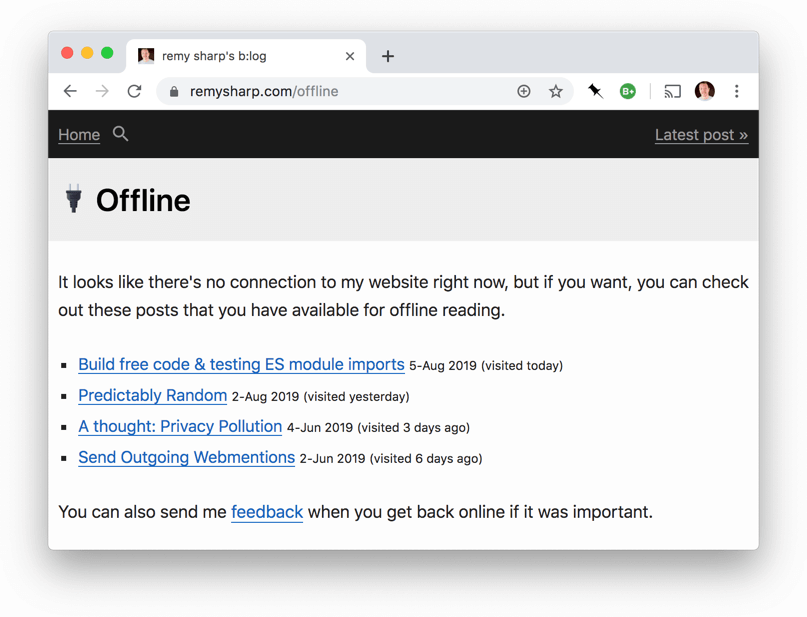
In the service worker this is handled by the following lines:
self.addEventListener('fetch', event => {
/* this logic is trimmed down for brevity */
// only for HTML based requests
if (request.headers.get('Accept').includes('text/html')) {
event.respondWith(
fetch(request) // try the network first method
.then(response => {
// if we have a 200 success, cache the result
// in a cache called "v1/pages"
if (response.status === 200) {
caches
.open('v1/pages')
.then(cache => cache.put(request, response.clone()));
}
return response;
}).catch(() => {
// the catch fires if we're offline, so first we try the
// cache for a match, and if `response` is empty (or null)
// return the `/offline` page instead.
return caches
.match(request)
.then(response => response || caches.match('/offline'));
}) // end fetch
); // end event.respondWith
return;
}
})
However, the interesting part is how we retrieve the recently visited posts.
Showing the history
When I'd chatted to Jeremy about his offline/recently visited page I realised since the cache API is only for requests and responses, the metadata required for a history page (such as post title) would have to be stored elsewhere. Jeremy (IIRC) stores his metadata in localStorage.
When I took my first stab at an implementation I used IndexedDB (along with Jake Archibald's idb keyval script). Then each page you visit needs to include the metadata about the post, which was adding a little more complexity to the problem.
Until, I realised I didn't need to store anything. HTML is the API.
Instead of capturing metadata, my posts, themselves in the markup, includes all the metadata about the post. So here's the logic without any additional store:
- Get all the entries stored in my
v1/pagescache - Get the URL from
request.url - Get the HTML from
await cache.match(request).then(res => res.text()) - Pattern match out the
<title>(.*)</title>text - Capture the publish date - in my case it's part of the URL, in Jeremy's case it's in the
<time>tag
In you're concerned that using a regex is brittle, the HTML could be put inside a DOM parser and queried out again. You can see that idea in action here (open the browser console) using code such as:
const p = new DOMParser();
const dom = p.parseFromString(html, 'text/html');
console.log(dom.querySelector('time').getAttribute('datetime'));
For my offline listings code, the actual code looks like this:
async function listPages() {
// since my cache names are versioned, look for the one that
// includes "/posts"
const cacheNames = await caches.keys();
// results is recently visited blog posts
const results = [];
for (const name of cacheNames) {
if (name.includes('/posts')) {
const cache = await caches.open(name);
// get a list of all the entries (keys are requests)
for (const request of await cache.keys()) {
const url = request.url;
// this regex gets both the publish date of the post,
// but also ensures the URL is a blog post
const match = url.match(/\/(\d{4})\/(\d{2})\/(\d{2})\//);
if (match) {
const response = await cache.match(request);
// capture the plain text HTML
const body = await response.text();
// regex for the title of the post
const title = body.match(/<title>(.*)<\/title>/)[1];
results.push({
url,
response,
title,
// published date is from the URL
published: new Date(match.slice(1).join('-')),
// last visited is the `date` prop in the response header
visited: new Date(response.headers.get('date'))
});
}
}
}
}
// now display the results
if (results.length) {
// sort the results, map each result to an <li> tag and put
// in the `ul#offline-posts` element
document.querySelector('ul#offline-posts').innerHTML = results
.sort((a, b) => a.published.toJSON() < b.published.toJSON() ? 1 : -1)
.map(res => {
// results in:
// <li><a href="…">[ Title ] <small>[pubDate] (visited X days ago)</small></a></li>
let html = `<li><a href="${res.url}">${
res.title
}</a> <small class="date">${formatDate(
res.published
)} <span title="${res.visited.toString()}">(visited ${daysAgo(
res.visited
)})</span></small></li>`;
return html;
})
.join('\n');
}
}
The /offline page is going to do a bit of JavaScript, scraping text out of cached pages to show you recently browsed results. At first I felt like this may be a lot of work for the browser to be doing, but since it only happens in exceptional circumstances and in reality it takes a handful of milliseconds, the improved user experience is worth this (relatively) small hit.
Oh, and as it happens, this page is now in your recently visited list :)