Warning: this is a tale of geek's own adventure into the dark depths of old webby stuff that really doesn't work well!
In collecting coverage for the CERN project to recreate the first browser, the WorldWideWeb, I came across an interesting issue discussed on Metafilter.
Specifically:
MetaFilter seems to be configured to return a 403 (forbidden) if the User-Agent is set to 'request'…
So I figured the WorldWideWeb simulator should send the right user agent. But what should it be, and I mean, how hard could it be…?
The obvious ways
A quick google frustratingly yielded zero results (or at least for the few I tried). Which frankly was a bit odd, but the WorldWideWeb was indeed a prototype browser and it's possible it dropped out of circulation before web sites started collecting this data.
Next "obvious" approach, make a request with the WorldWideWeb browser to a server where I can see the logs. Easier said than done. For the time being, I don't have a NeXT machine to hand, my VirtualBox based emulator can't run the WorldWideWeb.app (because my machine is Intel based and the .app was compiled for "Motorola 68K"…apparently).
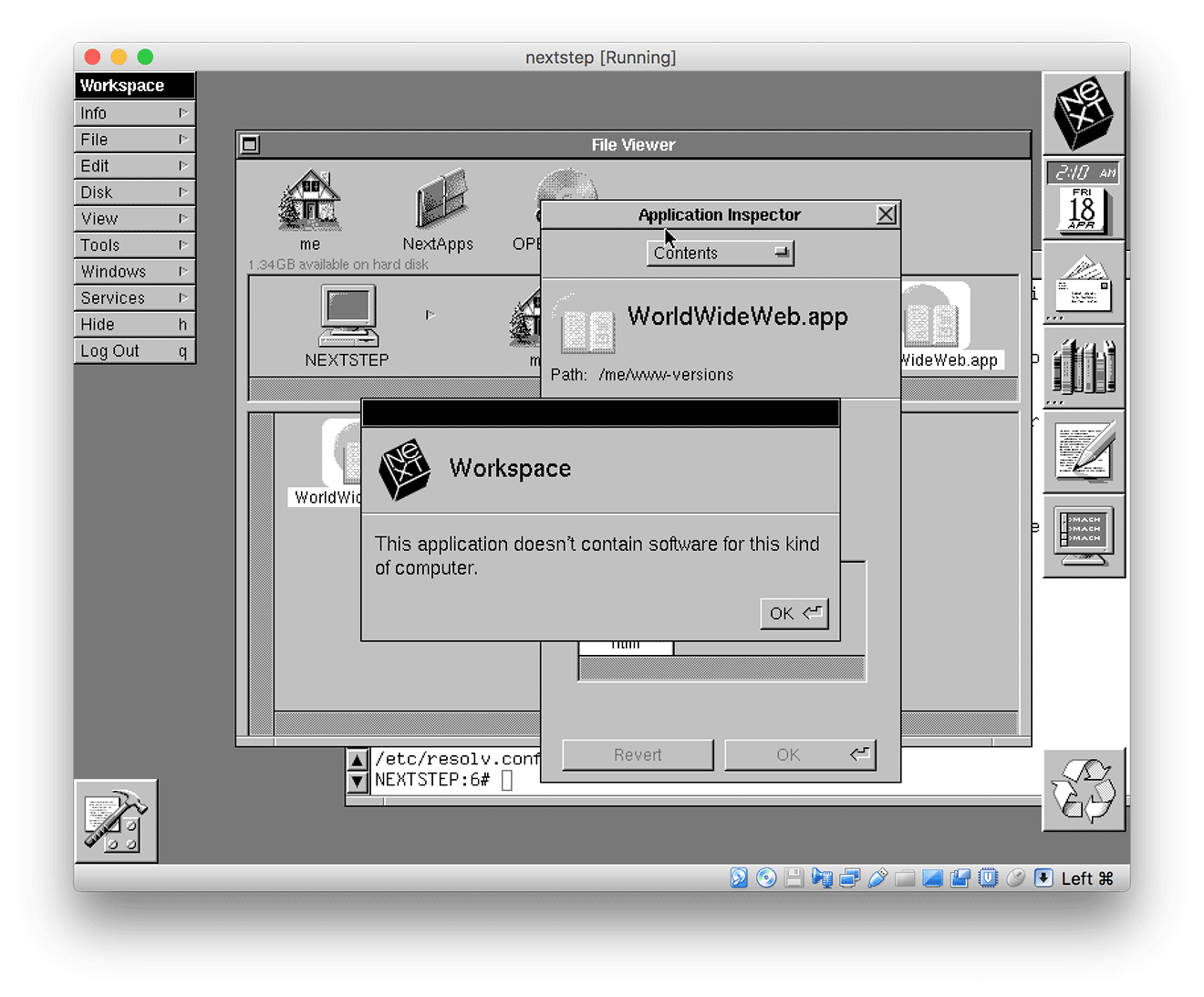
In search of strings
I had a copy of some of the source code to the WorldWideWeb browser, but only from 0.12 - which yields zero results for a any user agent string using tools like grep and ack.
Another tool I can use is the strings unix command. This tool will literally print out all strings (printable characters). There's lots of interesting bits to be found (including all the "about panel" text), but no dice.
However, all WorldWideWeb before 1.0 wouldn't have a user agent. Silly me, pre-1.0 was pre-HTTP 1.0, and HTTP 0.9 was a very different beast.
HTTP 1.0 introduces headers
The WorldWideWeb browser was released before HTTP 1.0. HTTP 0.9 is very different from 1.0 in that it's extremely sparse. All you have to send to a server is GET /url\n\n and the server will respond.
So it makes sense that we wouldn't find any strings with a user agent.
Running the strings command on WorldWideWeb v1.0 does find something, but it's not that useful either:
$ strings ./WorldWideWeb | grep -i agent
User-Agent: %s/%s libwww/%s%c%c
This is the first version that the user agent appears (my versions go up to 0.16 then jump to 1.0). This would also suggest that WorldWideWeb v1.0 therefore also supports HTTP 1.0 requests.
But what's %s/%s? In the second part, after libwww this would be the version for the core parsing library. The libwww version might be easier to ascertain (or even guess) as we can probably find historical versions for around the early 1990s.
It's the first part of the user agent string that I want. So I returned to the emulators.
NeXT with Previous
There's a project called Previous that's been running for years that provides a much fuller emulation of the NeXT system environment. In fact there's an online web hosted version of Previous running the WorldWideWeb browser that you can try out at oldweb.today (though at time of writing, the server wasn't responding…).
Importantly, Previous is based on the Motorola 68K architecture, which means I can run the WorldWideWeb browsers that I've found on the web.
Once Previous is up and running locally (on my mac - and I'll probably write this up separately another day), the trick is then being able to make a request and seeing what user agent is sent.
However, I'm faced with new problems: the Previous emulator can't access the open web (aka outside itself).
So what my options?
Ways to see a request
None of these methods work, but it's useful to know (of course if you know already, or don't care - please skip ahead 😉).
Start a server
Yep, sure. We could spin up apache with logging. But we don't have it (because it was written in 1995, and in fact, Tim Berners-Lee wrote the first http server which we did find that program on the real NeXT machine, but that was two weeks ago and I'm not at CERN anymore!).
Or Python in a single line using:
$ python2 -m SimpleHTTPServer 8000
But we don't have Python either. Nor Perl as it happens. And no, we don't have Node. Though Python and Perl (and I think Ruby these days) tend to ship with unix based operating systems by default. This was before the year of default I guess.
Bind to a port
netcat and more recently nc are superb commands for binding to a port and listening:
$ nc --listen localhost -p 8000
Also not available!
Sniffing traffic
There's also tcpdump which can listen in to requests (sort of an ear against the tubes as it were) - this example listens to all requests between info.cern.ch and our host machine:
$ sudo tcpdump host info.cern.ch -v
Of course we don't have any of these tools. In fact, there's very little we do have on the NeXT machine:

There are of course other ways, and please trust me when I say I tried!
For the eagle-eyed reader, you'll notice there's a distinct lack of anything that can help. I can't even compile .c programs on this machine without requiring some external tooling…
Previous Branches to the rescue
Somehow, the Previous project has been worked on in very recent days, and there was a branch tucked away that adds network support to the emulator. Yay!*
* Though in reviewing this in the broad light of day, I think the networking functionality may have been there all along…
Once I had reconfigured the Previous emulator, though it still couldn't reach the outside world (and I suspect this is either name server failing or possibly related to the fact the clock won't set beyond 2012 in the NeXT machine), it can reach my host environment.
This means I can run nc on my host (my Mac) and watch for the user agent.
I present…
So, after all that, what was the user agent for the WorldWideWeb version 1.0? I present to you:
CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.07
Why it's version 1.1 in the string and not 1.0, I've no idea, but there you go.
I suspect this wasn't the first user agent too, but that'll be for another day of digging.
Stretch goal: headers
Since I could now connect to a server, I decided to see what each version of the WorldWideWeb browser sent. Again, pre-1.0 WorldWideWeb didn't support HTTP 1.0, so I ran an HTTP 0.9 server and echoed out the request.
Here's what is sent to the server for each major version of the WorldWideWeb browser.
v0.16 WorldWideWeb
GET /
Yes, HTTP 0.9 is that simple!
v1.0
GET / HTTP/1.0
Accept: text/plain
Accept: text/html
Accept: audio/basic
Accept: image/x-tiff
Accept: application/postscript
User-Agent: CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.07
The browser now supports the <img> tag, and…apparently…audio too?!
v2.02 Nexus (renamed from WorldWideWeb after apparently the web was going to be a "thing"!)
GET / HTTP/1.0
Accept: */*; q=0.300
Accept: application/octet-stream; q=0.100
Accept: text/plain
Accept: text/html
Accept: */*; q=0.050
Accept: audio/basic
Accept: image/x-tiff
Accept: image/gif; q=0.300
Accept: application/postscript
User-Agent: CERN-NextStep-WorldWideWeb.app/1.1 libwww/2.16pre1
Probably the most interesting aspect to these headers is that image support not only lands (in the TIFF form at v1.0), but starts to expand to include GIFs in version v2.02.
That's all for now. I hope you enjoyed this journey into the depths of finding a user agent. Oh, and I did update the WorldWideWeb simulator and now metafilter.com works :)