The day's work has really started to intensify, particularly as the pressure mounts (certainly in my head) that the project needs to be fairly usable over the next couple of days.

It's also the first and last day that the whole team is together. Brian Suda arrived from Iceland last night (Tuesday) and John Allsopp returns to Australia on Thursday morning.
The working day
We're working out of a lab next to the data centre by day, arriving around 9am (having breakfast together at 8:30). We worked through to around 1:30pm breaking for lunch then returned to work until around 7pm.

The days previously had been broken up by visits and short expeditions and I was a little worried we needed full working days. Today we had that - and it was intense.
I suspect the rest of the week will be like this, particularly as the end of week deadline looms and my primary aim is to have a nearly working simulation of the WorldWideWeb.
By the end of the working day, my eyes are sore and there's a constant low background headache. My brain on the other hand is raring to keep coding - so I'm a little at odds!
Excavation
Kimberly Blessing sitting next to me during the day has been working their way through the original source to the WorldWideWeb browser (more of a revisit of the work they did back in 2013's Line Mode Browser source).
Kimberly has also been documenting the nuggets of hidden stories in the source written back in 1990.
I personally find it fascinating because right there in the code you can see a state machine that's parsing the stream of text from the network connection, building up what was a pre-DOM0 representation of content.
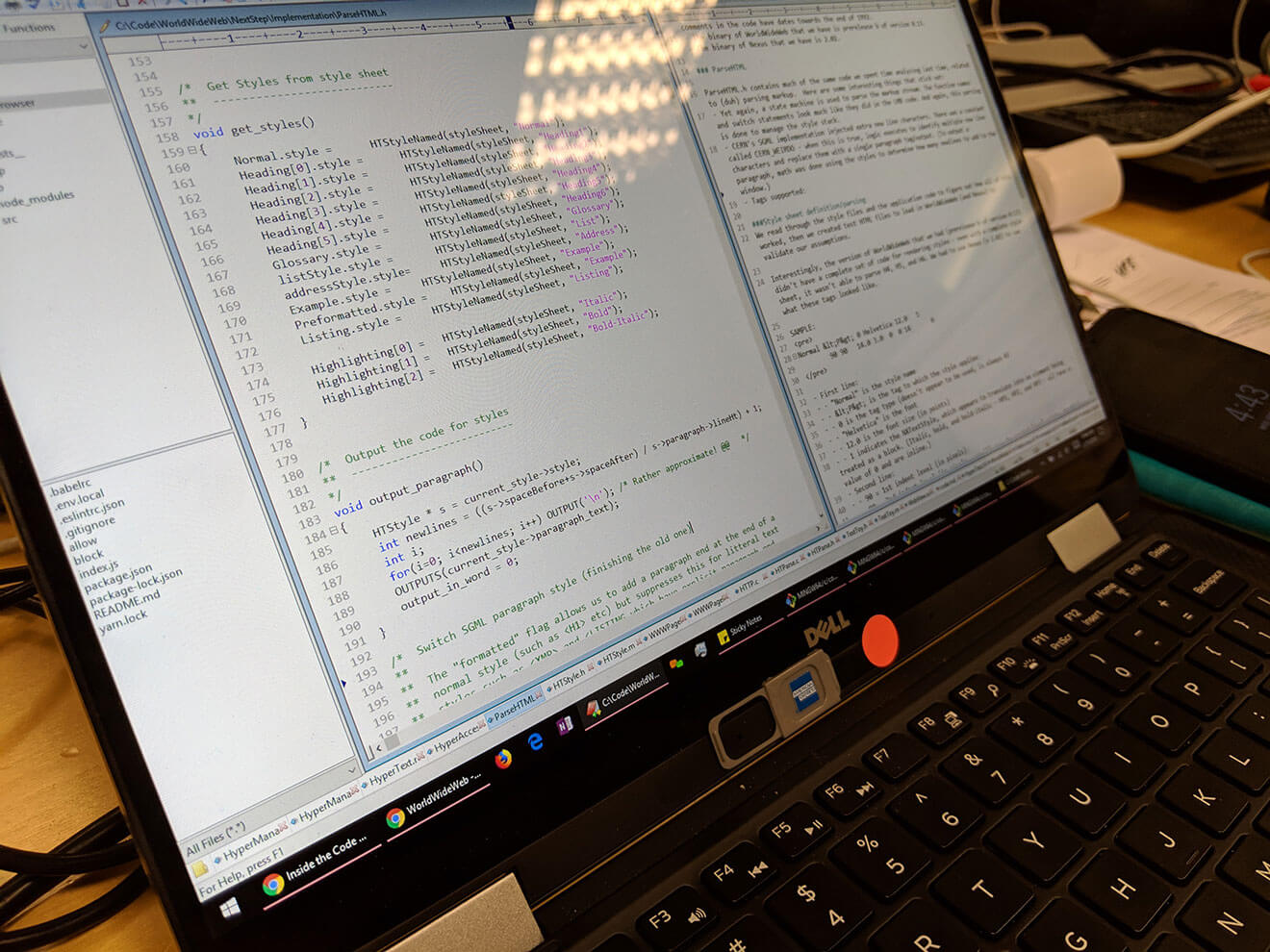
One function that I think is brilliant (in an über geeky way) is the output_paragraph photographed about. Kimberly had worked through the code thoroughly enough to work out that this particular function is what adds the margin to paragraphs. Except, they're not paragraphs as we'd know them.
The parser expects to see the following "markup":
This is my first paragraph, now if I wanted to break it up,
I'd use this following tag:
<P>
Then this would be the second paragraph. Whereas in today's
browser parsers would see __this__ line as being *nested*,
but in 1990's browsers, that tag only separates lines.
So there really wasn't a DOM at all. Of course not. This was pre DOM days. Tim Berners-Lee was parsing the text to render into a NeXT interface component like a NSText element. Probably closer to a RichTextFormat element.
You can see this in action on the Ted Nelson and Xandadu page:

You can see the paragraph lines separated, but in the original source there's no such thing (and a modern browser will render it completely differently): http://info.cern.ch/hypertext/WWW/Xanadu.html
As Jean-François Groff put it*:
The WorldWideWeb was a word processor plus HTTP.
* Not a direct quote, sorry!
Progress?
From my seat, it doesn't look like I've made a lot of progress, but there's definitely code being written!
Angela Ricci has built up the pattern library of elements that are visible in the NeXT operating system, and I've been slowly consuming them into the code I'm working on.
It turns out most of the work I've done so far (in the front end) is replicating the NeXT operating system - such as how windows work, menus (popup and tear off), window ordering and so on.
I've also had to work with the security team at CERN to make sure our backend code (little as it is) is secure and robust. That's to say: more invisible progress!
Still, it's not looking too bad, all this is running and interactive in the browser:
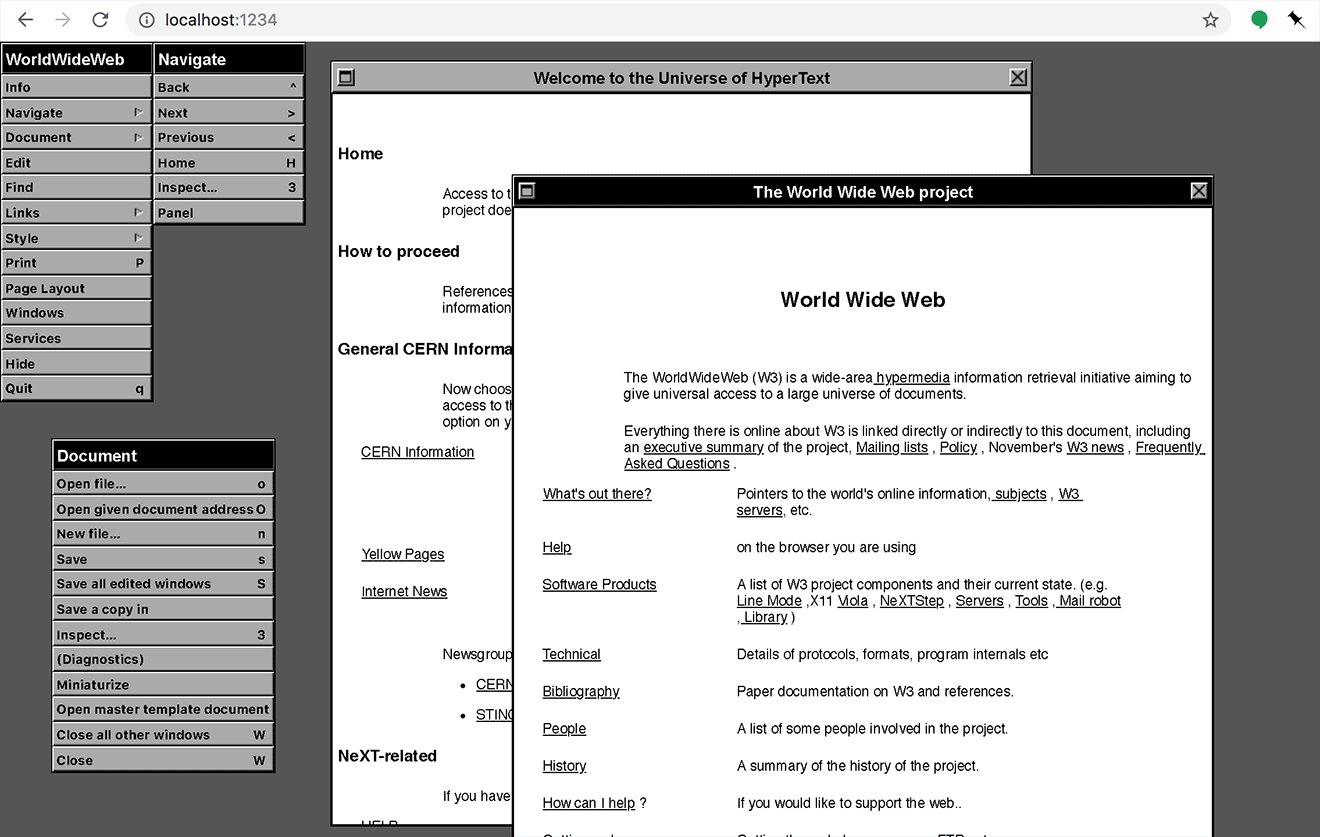
Tomorrow (Thursday) will be wiring up modal boxes, opening URLs, implementing the "navigate" function (which is another geek-cool feature) and then onwards to edit. Just two days left 😱