Though my body clock says it 7:30pm it feels like it's midnight—it's been a long, busy, interesting and surprisingly productive day.

(Oooh look, the old NeXTcube with WorldWideWeb browser can see yesterday's blog post!)
Digging into memories
The team had a short morning of coding and trying to overcome problems before shooting across the campus to meet Robert Cailliau for lunch at the main canteen, where team member, Jeremy Keith worked at picking his brain to the events some 30 years ago.
As much as this project is to recreate the original WorldWideWeb browser, it's also a digital archaeology (or excavation?) project which will be weaved into a story (by the wordsmiths of our team) and published online once our work is done.
We had already spent some time with Jean-François Groff who (as far as I understood) contributed on the WorldWideWeb browser and the libwww library (that powered a lot of http servers and clients). He shared a fun anecdote on how the Line Mode Browser (the 2nd browser) announced itself to the world.
If a user anonymously connected to cern.ch via telnet, instead of a static text notice, they would be presented with the output of the Line Mode Browser rendering a web page (I'd imagine the first web page) and, if I followed correctly, the user could interact and navigate through the the sign in software. Pretty smart!
Along with our own team efforts to document, there's CERN videographer and editors and then we also had the US mission team (sounds serious!) filming and interviewing.

All the data
We're also working right next to the main data centre for CERN (the picture at the start of this post) and we had a tour of the centre. Tonnes of great (geek) photo ops too!

CERN still make large use of tape based storage (since it's durable, it'll still work in 20 years of being at rest, and if it tears, it's taped back together and only a few files are lost!). I hadn't expected that, but makes a lot of sense.
Progress!
With all the activities it felt like we wouldn't make much tangible progress, but that wasn't so.
The morning was spent trying and experimenting to see if we could generate an aliased Helvetica font to replicate the visual feel of the text.
The font-smoothing: none were tried but just don't get the jaggies we want. I'm also experimenting with drawing all the text to canvas with imageSmoothingEnabled=false and then generating a jaggy png for each glyph to then be used for The Mother Of All text replacement techniques. But it might be overkill, so we've move font parity to a "stretch goal".
My main role is to write code to handle server requests and deal with the interaction. The server was written in a few hours on Monday (barring a few security tweaks), and the front end simulation is being written (quickly) using React (mostly for the benefit of code organisation via components).
So far though, I'm able to:
- Navigate to any URL
- Render it into a "window" (akin to the WorldWideWeb windows)
- Edit the content (yes, edit! I'll explain in another post)
- Navigate relative links (using double click - WorldWideWeb allowed editing, so a single click would place the cursor)
- Move windows about
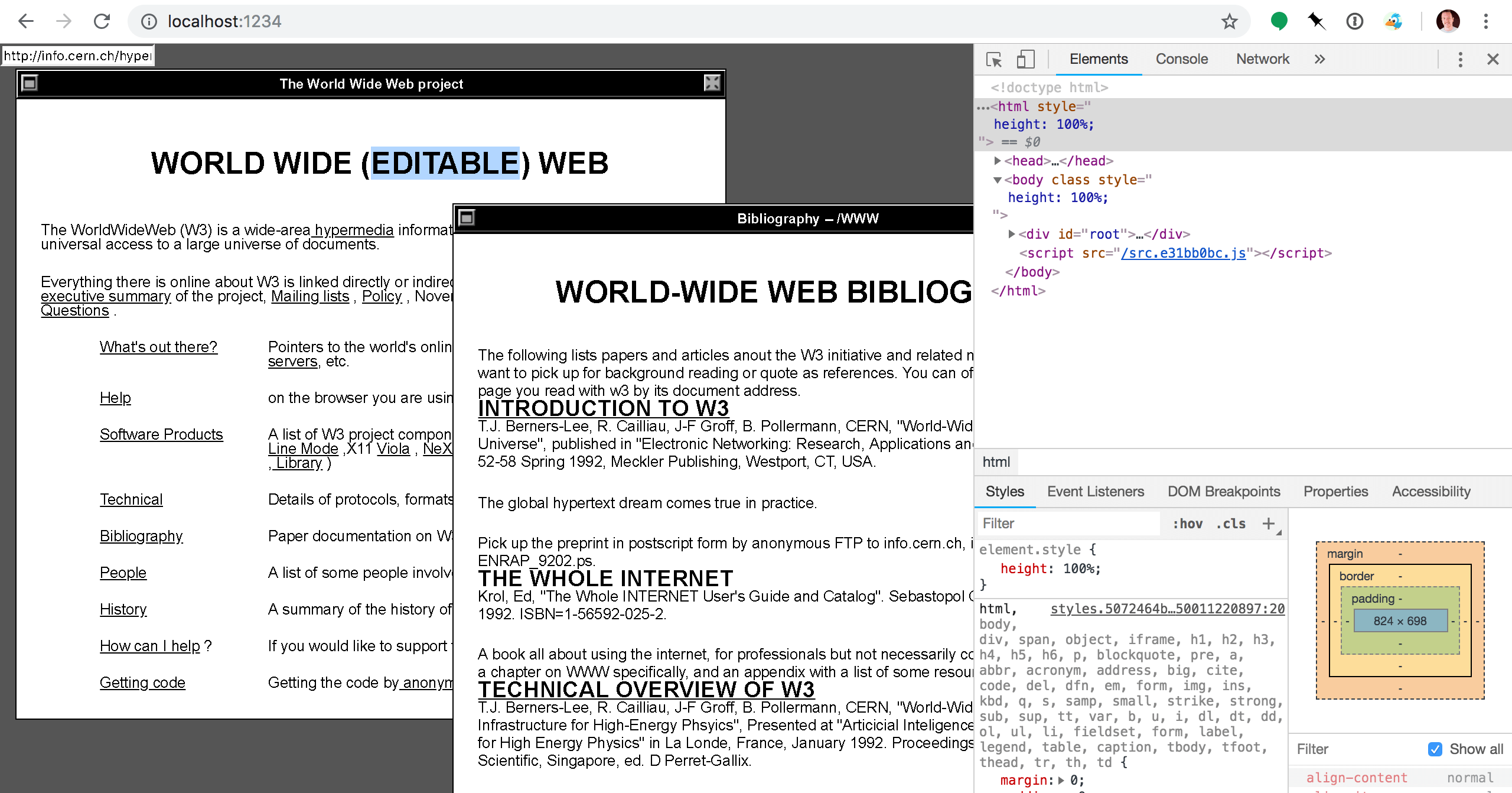
The day closed out with us trying to get the NeXTcube to browse a page. Team member Kimberly Blessing finally managed to get a binary of (one of) the original WorldWideWeb browsers onto our NeXTcube machine (oddly had a number of other browsers, just not the one we needed).
The machine also needed special network connectivity to connect which we didn't have on Monday. From there we were able to view pages as they had been viewed in the early 90s.
However trying to visit a public URL just didn't seem to work. That obviously didn't stop us :) Using some code I'd written a couple of years ago, I was able to run an HTTP 0.9 compatible server on my laptop that would then serve as a proxy to the "modern" web (ie. running HTTP 1, 1.1 or 2.0).
The HTML is then thrown back to the poor old machine for some interesting rendering challenges.
All in all though, seeing our own blogs being rendered on a browser that was written 30 years ago is pretty amazing. More so as a testament to the power of HTML. Though there was a lot of junk markup in the WorldWideWeb browser window, we could also very clearly read the content of our web sites.
Proving that HTML really is very, very backward compatible, as shown by Jeremy's adactio web site:
